By The Medical Futurist | April 9, 2019
How do you create a smart algorithm? Where and how do you get the data for it? What do you need for a pattern recognizing program to work well and what are the challenges? Nowadays, everyone seems to be building artificial intelligence-based software, also in healthcare, but no one talks about one of the most important aspects of the work: data annotation and the people who are undertaking this time-consuming, rather monotonous task without the flare that usually encircles A.I. Without their dedicated work, it is impossible to develop algorithms, so we thought it is time to sing an ode to the superheroes of algorithm development: data annotators.
Pattern recognizers in the quest to make healthcare better
By now, there’s no corner of the universe where artificial intelligence and smart algorithms have not appeared. Or at least the hype around them. The IDC projected that global spending on A.I. will reach $35.8 billion in 2019. The technology parades as the next Mozart you’ll listen to in awe, the next Cézanne you admire in the MoMA, as a compliant servant built into the oven, who texts the family when dinner is ready, or as a teaching assistant responding to your routine queries in an online course. There’s even an app which “helps you” judge the attractiveness of thousands of faces taken from This Person Does Not Exist, which generates fake portraits by mimicking details found in real photos.
Obviously, artificial intelligence or rather its most feasible form at the moment, artificial narrow intelligence developed through computer vision and natural language processing has many more, truly promising and useful applications, especially in healthcare. Smart software is used in radiology, pathology, cardiology, oncology and even psychiatry to recognize patterns, support diagnoses, and set up treatment pathways. It even surfaced at sub-specialties where you would expect them the least. For example, researchers at Stanford University, trained an A.I. system to increase the number of inpatients who receive end-of-life-care exactly when needed – meaning the smart algorithm is able to predict when very seriously ill patients are nearing the end of their lives.
How to make algorithms dream of cats?
The method for creating and then teaching an algorithm depends on the question it aims to solve. That’s the usual response to the general “how to” question, although certain characteristics could be discerned when it comes to creating smart software for medical use. Let’s say you want to have an algorithm to spot lung tumors in chest X-rays. For that, you will need to use tools for pattern recognition – the question doesn’t differ much from spotting cats on Instagram.
It sounds easy, doesn’t it? You say that if the image is of a furry animal with two eyes, four legs, that could be a cat. You describe its size, potential colors and how its cheek looks. Still, what if the animal is partly overshadowed by something? What if its playing and it only looks like a ball of fur? And ultimately, how do you even tell the computer all of this if it doesn’t understand legs, eyes, animals, just pixels?
“You will need millions of photos where those photos that have a cat in them are appropriately labeled as having a cat. That way, a neural network and in many instances, a so-called multilayered deep neural network can be trained using supervised learning to recognize pictures with cats in them”, David Albert, M.D., Co-Founder and President of AliveCor, the company that has been developing a medical-grade, pocket-sized device to measure EKG anywhere in less than 30 seconds, told The Medical Futurist. So, you won’t tell the algorithm what’s a cat, but you rather show it millions of examples to help it figure it out by itself. That’s why data and data annotation is critical for building smart algorithms.
What is data annotation?
The task of annotating data is a time-consuming and tedious work without any of the flare promised by artificial intelligence associated with sci-fi-like thinking and talking computers or robots. In healthcare, the creation of algorithms is rather about utilizing existing databases which mainly encompass imaging files, CT or MR scans, samples used in pathology, etc. At the same time, data annotation will be drawing lines around tumors, pinpointing cells or designating ECG rhythm strips. Thousands of them. No magic, no self-conscious computers.
That’s what Dr. Albert has been doing. He explained that “you must have accurately labeled and annotated data in order to develop these deep neural diagnostic solutions. For example, I may annotate or diagnose ten thousand ECGs over the course of several weeks, then another expert likely diagnoses the same ten thousand – and then we see where we disagree. After that, we have a third person, who is the adjudicator – who comes in and says, okay, regarding this five hundred where you disagree, this is what I think the answer is. And so it takes a minimum of three people to give you a reasonably confident answer that something is correct. Now, you can see it’s an awful lot of work. Deep neural networks to perform correctly in order to take advantage of big data require a tremendous amount of annotation work”.
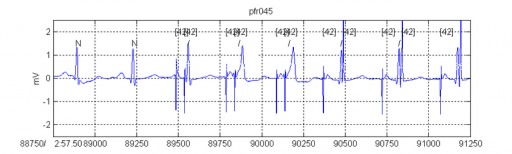
Counting cells and drawing precise lines around tumors
Katharina von Loga works as a consultant pathologist at The Royal Marsden NHS Foundation Trust, and she’s using software-based image analysis to monitor the changes of immune cells within cancerous tumors during therapy. The computer helps her count the cells after she designates carefully the set of cells she’s looking for. “I have an image of a stain in front of me, where I can click on the specific set and annotate that that’s a tumor cell. Then I click on another cell and say that’s a subtype of an immune cell. It needs a minimum of all the different types I specified, only after that can I apply it to the whole image. Then I look at the output to see if I agree with the ones that I didn’t annotate but the computer classified. That’s the process you can do indefinitely,” she explained.
Sometimes data annotators not only need great skills for pattern recognition and medicine, but it is also beneficial if they are good at drawing. Felix Nensa works as a consultant radiologist at the University Hospital Essen, more specifically at the Institute of Interventional Radiology and Neuroradiology. He explained the hardships of data annotation through an example in a new medical subfield called radiomics. “We identified a cohort of 100-200 patients with a certain type of tumor and we want to predict if the tumor responds to a certain therapy. In order to do it, you have to do a full segmentation of the tumor, a CT scan. If it’s lung cancer than you have the full CT scan of the lung which includes slices of the lung in a particular slice thickness – let’s say 5 mm. Then you have to draw a line around the tumor in each slide extremely precisely. It’s really a lot of work to draw a smooth line around this shape because such a tumor can be really large and most often it’s nothing like a ball.”
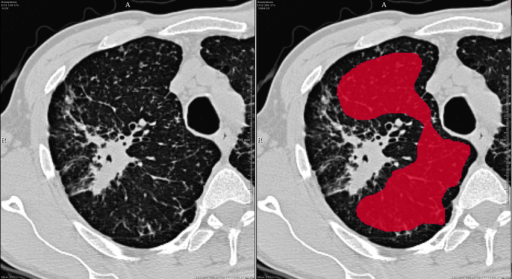
The hardships of data annotation
Katharina von Loga said that although it sounds perfect in theory that you can train an algorithm within a period of time to support medical work in pathology, the practice is much much more complicated. As medical data archives were (obviously) not created with mathematical algorithms in mind, it’s gargantuan work to try to standardize existing sampling processes or to have enough “algorithm-adjusted” samples. In her field, for example, it matters how the sample was processed from getting the specimen from the patient until it’s under the microscope. The staining method, the age of the sample, the department where the sample was produced – all factors to count in when it comes to making a decision about a sample for successful algorithmic teaching.
Beyond the problems of the massive variability in the samples, David Albert also mentioned the lack of experts for data annotation, as well as the difficulty to find databases of scale. Usually, the precision of an algorithm depends on the size of the sample – the bigger, the better. However, the leader of AliveCor mentioned how hospitals or medical centers, even really resourceful ones, don’t have enough data or enough annotations. For this reason, he believes that it will take companies like Google, Amazon, Baidu or Tencent with unlimited financial resources and a global footprint to really derive the kind of scale that you need to develop accurate A.I.
What is more, the human resources problem is aggravating. “There are only 30,000 cardiologists in the United States, all very-very busy. They don’t have time to mark ECGs. On the same note, there are only 25-40,000 radiologists – they don’t have time to read more chest X-rays. So, we’re gonna have to do something”.
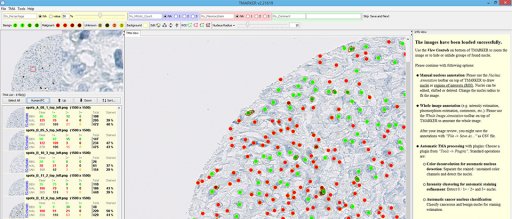
From medical students through online annotators to A.I. building its own A.I.
All three experts mentioned the option to employ medical students or pre-med students in university for simpler annotation tasks – to at least solve the human resources trouble. David Albert played with the thought of building online courses for training prospective annotators, who would afterward get some financial incentives for the annotation of millions of data points. Medical facilities could basically crowdsource data annotation through platforms such as Amazon Mechanical Turk. The process could employ the “wisdom of the crowds”. Imagine that you mix up a hundred chest X-rays, and present them in batches of fifty to online annotators. If there are a thousand annotators, you will find out what the majority diagnosis on those hundred images was. Although you won’t necessarily have experts of the field, statistics would say their responses will converge to the right answer, David Albert explained. He added that although the method was already ideated, it hasn’t been applied yet.
Another option would be the employment of algorithms also for annotation tasks – so basically building A.I. for teaching another smart software. Felix Nensa mentioned that they are building deep learning-based tools that can do completely automatic annotation by themselves and then the user just has to correct where this automatic process did not work well. But certain easier tricks could also speed up the tedious annotation procedure. He mentioned how convenient it would be to “build an app for your iPad, where you can really take a pen, and draw the tumor, which is obviously much more convenient than clicking with a mouse connected to a desktop computer”.
Katharina von Loga also mentioned how international and national committees are working on the standardization of the various sampling processes, which could really ease annotation work and fasten the building of algorithms. All these could lead to better and bigger datasets, more optimized data annotation and more efficient A.I. in every medical subfield.

What will the future bring for smart algorithms in healthcare?
David Albert expects the widespread appearance of smart algorithms to happen in the next five to ten years, so the medical community hopefully doesn’t have to wait long until the current transition period gives way to the ultimate era of A.I. “We will have much more sophisticated artificial intelligence for healthcare. It would be augmenting doctors and allowing them to return to being physicians, not just documenters”, he said referring to the phenomenon that US doctors are burdened by administrative tasks considerably adding to the problem of physician burnout.
Although Katharina von Loga only mentioned it will still take years until a significant number of doctors will recognize the benefits of smart algorithms, she would encourage every pathologist to get from the microscope to the screen. “I learn so much by just looking at the computer. It’s so interesting to see what it gets right. Sometimes I struggle to see something because the staining might be very faint, while the algorithm catches it instantly. At another time, the computer is completely off the road, while for the human eye, the answer is obvious. It’s just really exciting to see our different approaches and get it first-hand how powerful the combination of humans and computers is. That’s the one that gives the best output,” she explained. While we cannot emphasize it enough, it’s reassuring to hear it from others, too. Artificial intelligence will not replace physicians, the combination of their work with that of fellow medical professionals should be the direction to take for the future. However, we also see that doctors who don’t use algorithms might get replaced by the ones who do.
While there will be (and should be) countless debates about the ways of cooperation between artificial intelligence and physicians, one thing is certainly clear. We will never have smart algorithms in healthcare without data annotators.
That’s why we felt the need to talk about and appreciate the experts who right now might be sitting in dark hospital rooms in front of computers and annotate radiology or ophthalmology images so that in an unforeseeable future, someone somewhere creates a useful and potentially lifesaving medical application from them. Without the unsung heroes of data annotation, we will never have artificial intelligence.
Kudos to all data annotators out there!